高并發(fā)外賣系統(tǒng)的演進 數(shù)據(jù)處理與存儲支持服務(wù)
隨著移動互聯(lián)網(wǎng)的普及,外賣服務(wù)已成為現(xiàn)代生活的一部分,而高并發(fā)外賣系統(tǒng)在面對海量用戶請求時,其數(shù)據(jù)處理與存儲支持服務(wù)經(jīng)歷了顯著的演進。本文將從系統(tǒng)演進的角度,探討數(shù)據(jù)處理與存儲支持服務(wù)在高并發(fā)外賣系統(tǒng)中的關(guān)鍵作用和發(fā)展路徑。
一、早期階段:關(guān)系型數(shù)據(jù)庫的局限性
在高并發(fā)外賣系統(tǒng)的初期,業(yè)務(wù)量相對較小,系統(tǒng)主要依賴關(guān)系型數(shù)據(jù)庫(如MySQL)進行數(shù)據(jù)存儲。這種架構(gòu)簡單易用,但面對用戶訂單的快速增長、實時庫存更新和配送狀態(tài)跟蹤等高并發(fā)場景時,關(guān)系型數(shù)據(jù)庫的瓶頸逐漸顯現(xiàn)。例如,數(shù)據(jù)庫連接數(shù)限制、讀寫性能下降,導(dǎo)致系統(tǒng)響應(yīng)延遲,影響用戶體驗。此時,系統(tǒng)主要采用垂直擴展(如提升硬件性能)來緩解壓力,但成本高昂且擴展性有限。
二、演進中期:引入分布式緩存與讀寫分離
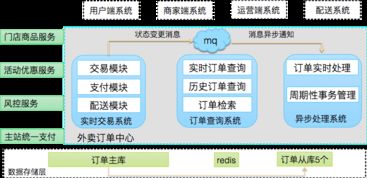
為應(yīng)對高并發(fā)挑戰(zhàn),系統(tǒng)開始引入分布式緩存(如Redis)來緩存熱點數(shù)據(jù)(如菜單信息、用戶會話),減少數(shù)據(jù)庫的直接訪問壓力。同時,通過讀寫分離技術(shù),將讀操作分流到從庫,寫操作集中在主庫,提升了系統(tǒng)的吞吐能力。這一階段還采用了消息隊列(如Kafka或RabbitMQ)來處理異步任務(wù),例如訂單創(chuàng)建后的通知和日志記錄,確保系統(tǒng)的可靠性和可擴展性。數(shù)據(jù)處理方面,系統(tǒng)開始使用批處理工具(如Hadoop)對歷史訂單數(shù)據(jù)進行分析,以優(yōu)化庫存和配送策略,但實時性仍有限。
三、現(xiàn)代階段:微服務(wù)與NoSQL數(shù)據(jù)庫的整合
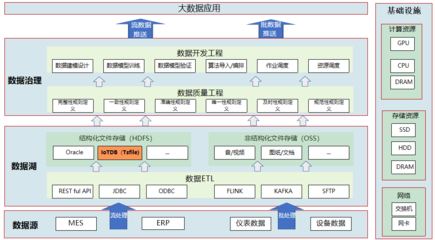
隨著業(yè)務(wù)復(fù)雜度的增加,外賣系統(tǒng)演進為微服務(wù)架構(gòu),將訂單、支付、配送等模塊解耦,每個服務(wù)獨立部署和擴展。在數(shù)據(jù)處理與存儲方面,系統(tǒng)廣泛采用NoSQL數(shù)據(jù)庫(如MongoDB用于存儲非結(jié)構(gòu)化數(shù)據(jù),Elasticsearch用于快速搜索訂單),并結(jié)合時序數(shù)據(jù)庫(如InfluxDB)處理實時監(jiān)控數(shù)據(jù)。數(shù)據(jù)存儲支持服務(wù)通過分布式文件系統(tǒng)(如HDFS)和對象存儲(如AWS S3)來管理大規(guī)模數(shù)據(jù),確保高可用和持久性。實時數(shù)據(jù)處理框架(如Apache Flink或Spark Streaming)被用于實時分析用戶行為和訂單趨勢,提升了系統(tǒng)的智能化水平,例如動態(tài)定價和智能推薦。
四、未來展望:AI與云原生技術(shù)的融合
未來,高并發(fā)外賣系統(tǒng)將向更智能、更彈性的方向發(fā)展。數(shù)據(jù)處理將深度融合AI技術(shù),通過機器學習模型預(yù)測需求峰值和優(yōu)化資源分配;存儲支持服務(wù)將基于云原生架構(gòu)(如Kubernetes和Serverless),實現(xiàn)自動擴縮容和成本優(yōu)化。同時,邊緣計算的引入將進一步提升數(shù)據(jù)處理速度,減少延遲。總體而言,數(shù)據(jù)處理與存儲支持服務(wù)的演進將持續(xù)推動外賣系統(tǒng)在高并發(fā)場景下的穩(wěn)定性和效率。
高并發(fā)外賣系統(tǒng)的演進不僅依賴于技術(shù)創(chuàng)新,還在于數(shù)據(jù)處理與存儲支持服務(wù)的不斷優(yōu)化。從傳統(tǒng)數(shù)據(jù)庫到分布式架構(gòu),再到智能云原生,每一步都體現(xiàn)了對高并發(fā)挑戰(zhàn)的應(yīng)對策略。未來,隨著技術(shù)的進步,這一領(lǐng)域?qū)⒂瓉砀嗤黄疲瑸橛脩籼峁└鲿场⒖煽康姆?wù)體驗。
如若轉(zhuǎn)載,請注明出處:http://www.zeifo.cn/product/13.html
更新時間:2026-01-18 02:18:06