Python數據分析實戰 抓取課工廠網站數據與深度分析
在數據驅動的時代,Python憑借其強大的庫支持已成為數據分析和網絡爬蟲的首選工具。本文將以“課工廠”網站為例,詳細介紹如何使用Python抓取網站數據,并進行數據處理、存儲與分析的全流程實踐,旨在為數據分析初學者和從業者提供一個完整的實戰案例。
一、數據抓取:使用Python爬蟲獲取課工廠網站信息
- 環境準備與工具選擇
- 安裝Python 3.x版本,并配置好開發環境(如Jupyter Notebook或PyCharm)。
- 核心庫安裝:使用pip安裝requests、BeautifulSoup、pandas、sqlite3等庫。requests用于發送HTTP請求,BeautifulSoup用于解析HTML,pandas用于數據處理,sqlite3用于數據存儲。
- 分析網站結構并設計爬蟲策略
- 訪問課工廠網站,通過瀏覽器開發者工具(如Chrome的Inspect)分析頁面結構,確定目標數據(如課程名稱、價格、講師、評分等)所在的HTML標簽。
- 設計爬蟲流程:發送請求 → 解析響應 → 提取數據 → 存儲數據。注意遵守robots.txt協議,并設置合理的請求間隔以避免對網站造成負擔。
- 編寫爬蟲代碼示例
- 使用requests庫模擬瀏覽器請求,獲取網頁內容。
- 利用BeautifulSoup解析HTML,通過CSS選擇器或find方法定位數據元素。
- 將提取的數據整理為字典或列表形式,便于后續處理。
二、數據處理與存儲:清洗、轉換并保存數據
- 數據清洗與預處理
- 使用pandas庫將爬取的數據轉換為DataFrame,方便進行結構化操作。
- 處理缺失值:對于空值或異常數據,可選擇刪除、填充或插值方法。
- 數據標準化:例如,將價格字符串轉換為數值類型,或統一日期格式。
- 數據存儲方案
- 本地存儲:將DataFrame保存為CSV或Excel文件,便于快速查看和共享。
- 數據庫存儲:使用sqlite3或MySQL等數據庫,實現數據的持久化和管理。例如,創建課程信息表,并將清洗后的數據插入表中。
三、數據分析:挖掘課工廠數據的價值
- 描述性統計分析
- 計算課程價格的平均值、中位數、標準差等,了解價格分布情況。
- 分析講師授課數量排名,識別熱門講師。
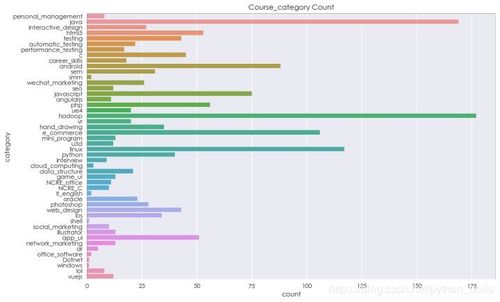
- 可視化展示:使用matplotlib或seaborn庫繪制柱狀圖、餅圖等,直觀呈現課程類別占比或評分分布。
- 深入洞察與趨勢發現
- 關聯分析:探索課程價格與評分、講師經驗之間的關系。
- 文本分析:對課程描述進行關鍵詞提取,了解熱門主題趨勢。
- 預測模型(進階):基于歷史數據,嘗試構建線性回歸模型預測課程受歡迎程度。
四、支持服務與優化建議
- 自動化與擴展性
- 將爬蟲腳本部署為定時任務(如使用cron或APScheduler),實現數據自動更新。
- 考慮使用Scrapy框架提升大規模爬取效率,并集成代理IP應對反爬機制。
- 數據安全與合規性
- 確保爬蟲行為符合網站使用條款,避免侵犯隱私或版權。
- 對存儲的數據進行加密備份,防止泄露。
- 服務化應用
- 將分析結果通過Flask或Django框架構建Web應用,提供數據查詢和可視化界面。
- 結合API服務,為其他系統提供課程數據支持。
通過本實例,我們展示了Python在數據分析領域的強大能力——從數據抓取到存儲,再到深度分析,形成了一個閉環流程。課工廠網站的數據分析不僅幫助用戶理解課程市場,也為優化課程推薦和服務提供了數據支撐。隨著技能的提升,讀者可進一步探索機器學習、實時分析等高級應用,讓數據真正驅動決策與創新。
如若轉載,請注明出處:http://www.zeifo.cn/product/58.html
更新時間:2026-01-18 02:13:22